Joe Letteri, dyrektor studia Wētā FX, opowiada o całkowicie nowym pipelinie animacji twarzy wykorzystanym w filmie „Avatar: Istota Wody”.
Nowa jakość animacji twarzy
Wētā FX opracowała całkowicie nowy pipeline dla animacji twarzy. Zespół po raz pierwszy opracował to przełomowe, nowe podejście w 2019 roku, ale firma ujawniła je dopiero na targach SIGGRAPH ASIA w Korei, co zbiegło się z premierą „Avatar: The Way of Water”. W tej dogłębnej dyskusji rozmawiamy bezpośrednio z Wētā FX Senior VFX Supervisorem Joe Letteri o tym, dlaczego podjął decyzję o opracowaniu nowego podejścia oraz z Karanem Singh, jednym z pozostałych autorów opracowania.
(Od lewej): Jon Landau (Producent Avatara), Joe Letteri (Wētā FX Senior VFX Supervisor) i Dan Barrett (Wētā FX Senior Animation Supervisor) podczas premiery Avatara w USA.
Nowy pipeline animacji twarzy
Nowy system animacji twarzy opiera się na przejściu od puppeta FACS (Facial Action Coding System) do krzywych włókien mięśniowych jako podstawy anatomicznej. Nowe podejście nazywa się Anatomically Plausible Facial System lub APFS i jest to nazwijmy „animatorocentryczny” (ang. animator-centric), tj. skupiony wokół pracy animatora, inspirowany anatomią system do modelowania twarzy, jej animacji i re-targetingu.
Jake Sully
Nowy system zastępuje wielokrotnie nagradzany pipeline FACS, który Wētā FX wykorzystywało konsekwentnie od czasu Golluma. Po wykorzystaniu do cna podejścia R&D (Research & Development) dla FACS przy produkcji filmu Alita: Battle Angel (2019), Letteri zdecydował, że system puppetowy oparty na FACS po prostu miał zbyt wiele poważnych problemów, takich jak separacja mięśni twarzy, pokrycie, liniowe wykorzystanie kombinatoryki i redundancja na szeroką skalę. Przykładowo, podczas gdy FACS mapuje zestaw póz twarzy, które oznaczają ekspresje wywoływane ruchem mięśni, aby uzyskać odpowiednią animację twarzy, rig kukiełkowy FACS może osiągnąć nawet 900 kształtów FACS dodanymi do rigga, aby umożliwić animatorowi osiągnięcie wiarygodnego efektu. Nie oznacza to jednak, iż FACS jest „zły”. Po prostu nie jest to system, który został zaprojektowany do animacji twarzy opartej na czasie. Nie został zbudowany w oparciu o mowę, ale raczej wyizolowanych ekspresji emocjonalnych. „Potrzebowaliśmy systemu, który pozwalałby artystom na bezpośrednią kontrolę nad tym, jak zachowuje się twarz” – komentuje Letteri. „System FACS emuluje twarz tylko z zewnątrz i ma bardzo ograniczone możliwości… to tylko system oparty na emocjach, koduje ekspresje. W FACS nie ma zakodowanego dialogu, a w większości to, co robimy, jest dialogiem.” Podczas gdy FACS może reprezentować dokładną wyizolowaną ekspresję, nie ma informacji o tym, jak przechodzić między pozami. „Kończy się na tym, że musisz jakby zgadywać, … to tak, jakbyś intuicyjnie określał przejście, co jest świetne, ale i trudne do utrzymania”, wyjaśnia Letteri. „Jest również bardzo „gumiasty”. System FACS może być bardzo gumiasty, ponieważ mamy owe zmiany stanu zachodzące w zasadzie liniowo dla całej twarzy, gdy przechodzi się z jednego do drugiego”.
Letteri i jego zespół postanowili zacząć od nowa i podejść do całego pipeline’u twarzy od zera. „Zacząłem patrzeć na problem i myśleć: Nie chcę już tego robić. To jest zbyt trudne. Jest, musi być lepszy sposób” – wspomina. „Zacząłem się cofać i po prostu patrzeć na mięśnie twarzy i to, jak są ułożone oraz jak wszystkie są połączone. Zdałem sobie sprawę, że jeśli odwzorujesz te połączenia, będziesz miał podstawę do stworzenia wielowymiarowej przestrzeni, która mogłaby opisać twarz”.
Zespół skupił się na fakcie, że gdy ekspresja jest wykonana, aktywowany jest mięsień, a pozostałe mięśnie aktywują się w tandemie lub są ciągnięte biernie. „Ze względu na sposób, w jaki mięśnie są połączone, w rodzaju sieci, która ściśle przypomina sieć neuronową”, rozumował Letteri. „Wtedy pomyślałem, dlaczego nie stworzyć sieci neuronowej, która jako podstawę wykorzystuje bezpośrednio mięśnie? Innymi słowy, wiele metod głębokiego uczenia się (ang. Deep learingu) próbuje nakarmić problem liczbami, dać mu wiele danych, a on będzie próbował znaleźć korelacje za ciebie. A ja pomyślałem, że nie, my właściwie już znamy korelacje, dlaczego więc nie zakodujemy tego jako naszej podstawy? Jeśli zagłębisz się w matematykę, to jest to duży łańcuch pochodnych. To podstawowy rachunek”. Zespół miał następnie powziął za cel stworzenie systemu, który daje animatorowi unikalny sposób reprezentowania dowolnej kombinacji ułożenia szczęki, oczu i mięśni. „Jako podstawa, jest to fantastyczne, ponieważ możemy teraz trenować system, aby spojrzeć na powiedzmy twarz Sigourney Weaver i spróbować rozszyfrować to, co robią 'mięśnie’, a następnie uruchomić inną sieć, która przeniesie to na postać.” Dodatkowo, dzięki krzywym mięśniowym, animatorzy mają teraz bezpośrednią kontrolę nad twarzą, mięsień po mięśniu. Ważnym jest jednak, aby zaznaczyć, że krzywe mięśniowe nie są zaprojektowane tak, by dopasować rzeczywiste mięśnie pod skórą jeden do jednego. Służą do rozwiązania problemu mimiki twarzy, ale w sposób, który animatorzy mogą kontrolować, a jednocześnie pasują do ruchów twarzy, uchwyconych z niesamowitą wiernością.
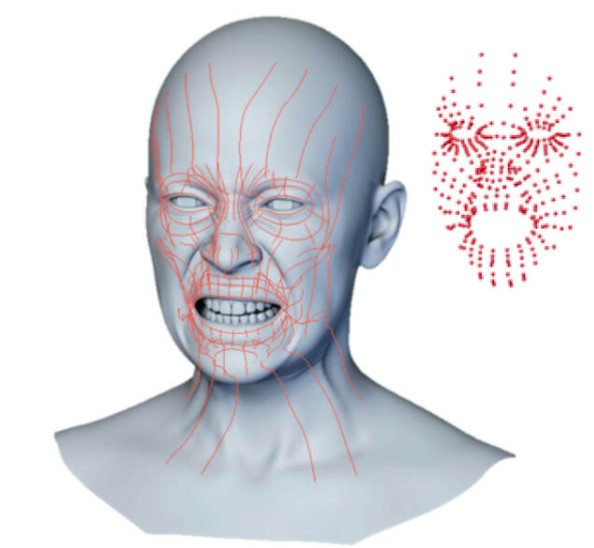
Nowy APFS opiera się na 178 krzywych włókien mięśniowych lub krzywych „naprężenia”. Krzywe te mogą się kurczyć lub rozluźniać, aby zapewnić precyzyjną i wierną ludzkiej mimikę. System end-to-end jest zarówno typu inward-out (twarz jest kierowana przez krzywe włókien mięśniowych), jak i outside-in (animator może „poprawnie” przeciągnąć i przesunąć twarz z powierzchni twarzy). System nie jest odwzorowaniem 1:1 ludzkich mięśni, ponieważ niektóre aspekty twarzy, takie jak krzywizna górnej wargi, są w rzeczywistości wynikiem działania szczęki i dolnych mięśni twarzy. System jest raczej zbiorem 178 krzywych, które pozwalają na anatomiczny zestaw kontrolek, ale nie na bezpośrednią emulację czy symulację ciała/mięśni. Ponadto, puppety FACS są zbudowane na podstawie liniowej kombinacji wyrażeń FACS, które nie obejmują rotacji. Aby uzyskać poprawną animację powiek, która naturalnie zawiera składową rotacji wokół gałki ocznej, należy dodać zestaw pośrednich kształtów FACS.
Krzywe mięśniowe (po lewej) i markery śledzące (po prawej)
Powieki
Każdy mięsień lub krzywa odkształcenia ma przypisaną wartość odkształcenia. Krzywe mięśniowe tak naprawdę nie ulegają skręceniu, lecz skurczeniu lub rozszerzeniu na podstawie wartości ich odkształcenia, w jej lokalnej przestrzeni. W pewnym sensie jest to procentowa zmiana długości. Rzeczywista liczba odkształceń krzywej jest bezjednostkowa, co pomaga w jej przenoszeniu na różne postacie. Wartości odkształcenia działają nie tyle w izolacji, co jako część zestawu. Obrazując, dla mrugnięcia powieki istnieją zarówno krzywe mięśniowe wzdłuż linii rzęs (poziomo), jak i ortogonalnie (pionowo, w górę i w dół, wokół oka). W tym przypadku krzywa pozioma nie zmienia wiele w rzeczywistej wartości odkształcenia, ponieważ obraca się nad gałką oczną, natomiast krzywe pionowe drastycznie zmieniają wartość odkształcenia. Ale najważniejsze jest to, że wraz z krzywą pionową skaluje się kształt krzywej mięśniowej – która pokrywa się z krzywą gałki ocznej. Podobne przejście w blendshape’ie pomiędzy otwartą i zamkniętą pozą, wywołałoby ruch w linii prostej od zamknięcia do otwarcia (bez ugięć wokół gałki ocznej). W Mayi można łączyć blendshape’y, by symulować zakrzywianie się powieki wokół gałki ocznej, ale to znowu zwiększa ich już niemałą liczbę.
Choć rozwiązania FACS pozwoliły na pewien poziom standaryzacji w zróżnicowanych rigach twarzy, sam FACS został zaprojektowany z psychologicznego punktu widzenia, aby uchwycać dobrowolne, rozróżnialne ekspresje twarzy. Ma wyraźne ograniczenia, gdy jest stosowany w animacji komputerowej. Jednostki akcji (AU) dla FACS muszą być łączone z odejmowaniem, aby uzyskać pożądaną ekspresję (AU łączą działanie wielu mięśni twarzy lub w ogóle nie angażują mięśni twarzy), lokalizację i kontrolę animacji (AU mogą być redundantne, przeciwstawne w działaniu, silnie powiązane lub wzajemnie się wykluczające). AU także tylko przybliżają złożone deformacje kształtu szczęki i ludzkich ust. Do budowy nowego systemu wykorzystano uczenie maszynowe. Wykorzystano 6000-8000 skanów (klatek) z 80 dynamicznych klipów ruchowych. Około 60% to pozy kształtowe (ang. shape poses) FACS, a 40% to ruchy generowane w trakcie mówienia. Ruchy każdego aktora zostały rozpoznane dzięki 340 markerom na podstawie zweryfikowanych ekspresji ground-truth (ręcznie zweryfikowanych, zatwierdzonych ekspresji). Pipeline APFS nie koduje tymczasowo żadnych informacji, pochodzą one z samego przechwytywania występów. Animacja naturalnie śledzi ruch i ekspresję aktora.
Szczęki i wargi otrzymują dodatkową uwagę w nowym systemie, „ponieważ jedną z rzeczy, które zauważyłem, gdy budowaliśmy system, jest to, że największy wpływ na układ twarzy ma szczęka”, opowiada Letteri. „Szczególnie w przypadku prowadzenia dialogu, szczęka jest w ciągłym ruchu. Jest to główny „sterownik” następujących po sobie zmian.” Dodatkowo, szczęka każdej osoby może poruszać się tylko po określonej krzywej. Żuchwa, czyli dolna kość szczękowa, jest przymocowana do czaszki poprzez staw skroniowo-żuchwowy i utrzymywana w miejscu przez więzadła i mięśnie. W związku z tym zakres ruchu szczęki może być odwzorowany dzięki prześledzeniu zestawu hipotetycznych punktów na szczęce. Kiedy odwzorowujemy zestaw takich punktów dla wszystkich możliwych dialogów i wypowiedzi danej osoby, otrzymujemy kształt „tarczy” (shield). Jest ona również znana jako Posselt’s Envelope of Motion lub tarcza Posselta. „Tarcza ma wbudowany system constraintów, tj. posiada sterownik opisujący ruch szczęki” – wyjaśnia Letteri. „Mięśnie zostają doczepione na jej wierzchu”. Dzieje się tak dlatego, ponieważ gdy zespół tworzy model dla dowolnego aktora, przygotowuje dopasowanie kryminalistyczne cyfrowego modelu czaszki do aktora. Następnie ustala zakres ruchu szczęki, po czym wykonuje „solving” przy użyciu kamer stereo HMC, aby uzyskać informacje o głębi. „Następnie przeprowadzamy analizę PCA (ang. Principal Component Analysis), aby uzyskać najlepsze możliwe dopasowanie, co generuje spójną siatkę (ang. mesh). Następnie dopasowujemy do tego szczękę i czaszkę” – dodaje. Jeśli zespół zajmuje się performance capturingiem, ruch i jego zakresy są już uwzględnione w trakcie jego odgrywania przez aktora. Jednak jeśli zespół animuje ręcznie, to ich kontroler dla szczęki ma tarczę z wbudowanym systemem constraintów. Animacja została zweryfikowana poprzez obserwację ułożenia zębów na tle obrazów przechwyconych z każdej kamery dla danego aktora.
PCA – w animacji twarzy, PCA może być wykorzystane do stworzenia modelu ekspresji twarzy poprzez analizę dużego zbioru przykładowych ekspresji i identyfikację kluczowych póz, które przyczyniają się do zmian w danych. Te kluczowe pozy mogą być następnie wykorzystane do skonstruowania modelu, przydatnego w generowaniu nowych ekspresji lub do interpolacji pomiędzy istniejącymi.
Bardzo starannie traktowane są także oczy aktorów. Model oka dopasowuje się do twardówki, rogówki i tęczówki aktora. Kierunek patrzenia oczu jest dostosowywany w każdej klatce poprzez obracanie gałek ocznych tak, aby model tęczówki wyrównał się z pierścieniem limbicznym i źrenicą, widocznymi na obrazach przechwyconych z każdej kamery. Oczy są bardzo trudne do śledzenia, ze względu na soczewkowanie oka i wykazywaną przez nie refrakcję. W celu weryfikacji ustawienia i uwzględnienia światła załamanego przez rogówkę stosuje się wiele kątów kamery. Nawet niewielkie wybrzuszenie przedniej części oka jest uwzględniane przy każdym obrocie oczu, aby zwiększyć ich realizm.
Ze względu na fakt, iż krzywe mięśniowe są tylko liniami, musi istnieć związek między naprężeniami mięśni a skórą cyfrowej postaci. Krzywe odzwierciedlają linie aktywności mięśni, ale są też osadzone wewnątrz samej twarzy. W tym przypadku twarz jest symulowana objętościowo z wykorzystaniem objętości czworościanowejj (tetrahedrycznej) dyskretyzującej tkankę miękką twarzy w pozie spoczynkowej (neutralnej). Rozwiązanie „tet” umiejscowione jest w modelu pomiędzy skórą a kośćmi czaszki i szczęki. Tety tworzą konceptualną lub matematyczną „galaretkę”. Pasywna, quasi-statyczna symulacja jest przeprowadzana na tej objętości tetowej dla całych sekwencji skanowania z wierzchołkami skóry i czaszki jako constraintami dla pozycji. Wykorzystując metodę elementów skończonych (MES), przeprowadza się „pasywną symulację” 135 000 tet (ograniczonych wieloma constraintami dla położenia, przesuwu i kolizji), klatka po klatce, co pozwala uzyskać anatomicznie wiarygodne zachowanie ciała. Wygenerowana w ten sposób „maska ciała” odgrywa rolę jedynie na etapie szkolenia.
Uwagę zwraca fakt, iż druga twarz to widok maski twarzy uzyskanej ze 135 000 tet, która, w połączeniu z krzywymi odkształceń (widocznymi nad czaszką), kontroluje deformację skóry, tworząc ostateczną ekspresję twarzy.
Podczas gdy mięśnie twarzy są często mięśniami wstążkowymi (płaskie i szerokie), krzywe APFS wymiaru szerokości nie posiadają. Tam, gdzie było to potrzebne, dodano dodatkowe krzywe, aby to uwzględnić. Krzywe mięśniowe nie są aktywnymi symulacjami mięśni, „i tak naprawdę animatorzy też tego nie chcą” – komentuje Karan Singh, profesor informatyki na Uniwersytecie w Toronto, który pracował nad projektem. „Oni (animatorzy) chcą kontroli klatka po klatce. Chcą kinematycznej kontroli deformacji. Naprawdę nie chcą być zmuszani do ustawiania konfiguracji (symulacji), a następnie ją odtwarzać, by przekonać się, jak aktywna symulacja przejmuje kontrolę.” Z tego powodu, jego zdaniem zespół wybrał reprezentację krzywych i „postanowił po prostu się ich trzymać”, dodaje. „Wykorzystaliśmy minimalny, absolutnie minimalny rodzaj reprezentacji parametrycznej, jaki mogliśmy”.
Neytiri
Karan Singh dołączył do zespołu w 2020 roku, tuż przed pandemią COVID, ponieważ przebywał w Nowej Zelandii jako wizytujący naukowiec. Choć jako pierwszy powie, że nie był głównym badaczem, odegrał główną rolę w przygotowaniu procesu do złożenia na SIGGRAPH ASIA i był w Korei na prezentacji z Byungkuk Choi Haekwang Eom i Benjaminem Mouscadetem, którzy przeprowadzili prezentację na żywo. Każdy z inżynierów miał konkretny cel i moduł jako część dużego rozwiązania end-to-end. Dokument ma właściwie 12 autorów, w tym Joe Letteriego i Karana Singha.
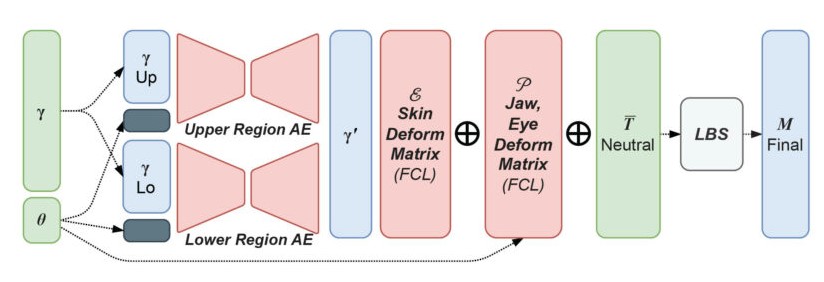
Singh napisał oryginalny kod blendshape’ów dla programu Autodesk Maya na początku swojej kariery, więc jest bardzo dobrze zaznajomiony ze szczegółowym kodem używanym wokół puppetów FACS. Singh wskazuje na sprytne wykorzystanie Autoenkoderów (AE) uczenia maszynowego (ML) w nowym pipeline’ie, aby utrzymać ekspresje w modelu. ML przekształca pipeline’y takie jak ten w Wētā, ale w sposób, który wiele osób jeszcze nie w pełni rozumie. Wiele pisze się o VAE (Variational Autoencoder – typ modelu głębokiego uczenia się wykorzystywany do zadań generatywnych, m.in. w animacji twarzy) i jego zastosowaniu jako narzędzi do podmiany twarzy w deepfake’ach, ale zespół APFS demonstruje tutaj, jak narzędzia ML, takie jak AE, są wykorzystywane wewnątrz złożonych pipeline’ów do wspomagania kluczowych zadań, podczas gdy nie są nadmiernie używane do uzyskiwania finalnych pikseli widzianej twarzy.
System może łatwo odbiec od modelu, gdy używa się tradycyjnych blendshape’ów FACS, ale przestrzeń rozwiązań jest ograniczona przez AE. „Kiedy tworzysz poprzez wczesne testy i dane treningowe dla poszczególnych postaci, ustalasz dla nich warunki brzegowe”, wyjaśnia Singh. „Autoenkoderw w pewnym sensie to koduje, więc nie jest to tylko ogólne ustawienie, które zadajesz. W rzeczywistości kodujesz bardzo specyficzny zestaw ekspresji aktora”. AE w sposobie konstruowania pipeline’u naprawdę skupia twarz w centrum uwagi i dosłownie na modelu.
Autoenkoder (AE), w pełni połączona warstwa matrycy deformacji twarzy (FCL), linearny blend skinning (LBS) prowadzące do finalnego outputu
Transfer bibliotek póz
Animatorzy są naturalnie przyzwyczajeni do posiadania bibliotek póz. I nie ma w tym niczego złego, ale pozy nie wymuszają ani nie kodują żadnego ruchu, a kombinatoryczne użycie może łatwo odejść od modelu. Aby zapewnić znajome środowisko pracy, zbudowano dla animatorów bibliotekę ruchu opartą na odkształceniach (ang. strain-based). To podejście typu outside-in zapewnia odwrotne mapping krzywych. Jednak biorąc pod uwagę sposób budowy systemu i zastosowanie autoenkodera, animator nie może przypadkowo odejść od zadanego modelu. Rozciąganie i kurczenie się mięśni może być intuicyjne, ale wywołanie wyrazu twarzy za pomocą wektora odkształcenia nie jest proste. Zespół zastosował autoenkoder (AE), by pomóc artystom, ograniczając wektory odkształcenia. Te pozostają w granicach wiarygodnie wyglądającej animacji twarzy. Przestrzeń rozwiązań modelu jest nazywana kolektorem ekspresji (ang. expression manifold). To animator określa, co jest prawdopodobne, oraz to animator może zdecydować się na celowe odejście od modelu. Jednak kolektor ekspresji jest dla niego szacowany przy użyciu wybranych samplów wielu wyrazów twarzy i odpowiadającego im zakresu wektorów odkształcenia lub ustawień.
Tuk (Trinity Bliss)
Deep Shape
W Avatar: Istota Wody wielu aktorów zostało uchwyconych w wodzie, ale większość ich animacji twarzy opierała się na wtórnym uchwyceniu na suchym lądzie, które następnie było miksowane z głównym ujęciem. Podczas wykonywania ujęć twarzy aktorzy nosili stereofoniczny head rig (HMC), który dzięki nowszej technologii nie był cięższy niż oryginalny HMC z Avatara 1.
Dzięki stałemu układowi stereo kamer HMC zespół Wētā opracował nowe, potężne narzędzie wizualizacyjne o nazwie Deep Shape. Obrazy stereo są wykorzystywane do zapewnienia trójwymiarowej rekonstrukcji w formie chmury punktów rzeczywistego ujęcia występu aktora, którą można oglądać pod dowolnym kątem. Obraz jest monochromatyczny i nie spoligonizowany, ale w dużym stopniu oddaje rzeczywiste ekspresje. Ta nowa wizualizacja daje animatorowi wirtualną kamerę, tak jakby twarz była filmowana zaledwie z odległości kilkudziesięciu centymetrów, bez zniekształceń szerokokątnych (efekt rybiego oka) i niecentrycznego kąta widzenia z którejkolwiek z dwóch kamer przechwytujących. Taki trójwymiarowy widok z głębią pozwala znacznie dokładniej oglądać ruch ust i szczęki i oceniać, czy późniejsza w pełni kontrolowana i zrekonstruowana animacja jest wierna początkowemu widokowi. Jest to tak niezwykle użyteczne narzędzie, że dziwi fakt, iż nikt wcześniej tego nie zaimplementował. Według naszej wiedzy, Wētā FX jest pierwszym zespołem, który z pełnym sukcesem osiągnął wizualizację Deep Shape. To kluczowe narzędzie referencyjne dla ekspresji ground truth, aby móc porównywać i oceniać emulację APFS. Jest to kolejna innowacja w nowym rozwiązaniu end-to-end opartym na APFS (Anatomically Plausible Facial System).
Reżyser James Cameron i aktor Sam Worthington za kulisami
Postarzanie
Zgodnie z powszechną praktyką, zespół animował cyfrowego sobowtóra aktora, który z dużą wiernością dopasowywał się do mimiki twarzy, a następnie przenosił animację do modelu postaci. Aby zmaksymalizować dopasowanie pomiędzy aktorem a twarzą postaci podczas transferu animacji, Wētā zaprojektowało proces treningu postaci tak, by współdzielić zachowanie mięśni aktora. Model twarzy postaci 3D ma w końcu ten sam wspólny autoenkoder odkształceń, identyczny jak u danego aktora. Skóra jest odwzorowana 1:1, a regiony oczu i szczęki są obsługiwane oddzielnie. Dzieje się to przy użyciu zdefiniowanych przez użytkownika, tzw. weight maps (mapa wagowa to siatka 2D lub obraz, który przypisuje wartość wagi każdemu wierzchołkowi lub punktowi w siatce tworzącej twarz; używana jest do kontrolowania ruchu lub deformacji twarzy podczas animacji różnych ekspresji), co pozwala na dokładniejsze oddanie ekspresji tych kluczowych części twarzy. Oczywiście, biorąc pod uwagę unikalny kształt Na’vi, zespół musi starannie dopasować rig szczęki aktora do postaci i wykorzystać go do skompensowania różnic w rozmieszczeniu zębów i anatomii czaszki.
Sigourney Weaver jako dr Grace Augustine, reżyser James Cameron oraz Joel David Moore (Norm Spellman) za kulisami.
System krzywych mięśniowych posiada zestaw krzywych rozciągających się w dół do obszaru szyi, aby umożliwić lepszą integrację z motion capturingiem ciała. Całkowicie osobno animujemy uszy, „powodem, dla którego nie zawracaliśmy sobie głowy ich rejestrowaniem, w tym konkretnym przypadku, jest to, że są one rodzajem efektu wtórnego”, mówi Letteri. „Uszy właściwie same niczego nie napędzają. Na’vi mają ekspresyjne uszy, które nie są w ogóle reprezentowane u ludzi. Istnieje więc osobny system do ich animacji.”
W filmie jest naturalnie mnóstwo retargetingu do Na’vi, ale co ważne są też dwa kluczowe retargetingi de-aging. Zarówno aktorzy Sigourney Weaver jak i Stephen Lang są retargetowani na młodsze postaci: Kiri i młodszego Quaritcha. Chociaż można by zbadać zmianę wartości odkształcenia, aby zasymulować rozluźnienie i starzenie się mięśni twarzy, Letteri zaznacza, że retargetowanie w pełni to zrekompensowało, a wartości odkształcenia nie musiały być „rozluźnione” lub rozciągnięte. „Myśleliśmy o zrobieniu tego, ale to dodałoby poziom niepewności” – komentuje Letteri. „Pomyśleliśmy więc, że najpierw spróbujmy tego w retargetingu, bo jeśli zadziała, to jest to znacznie prostsze rozwiązanie. I tak właśnie zrobiliśmy. I udało nam się, że działa to dla nas dobrze”.
Autorami oryginalnego artykułu „Animatomy: an Animator-centric, Anatomically Inspired System for 3D Facial Modeling, Animation and Transfer” SIGGRAPH ASIA są Byungkuk Choi, Haekwang Eom, Benjamin Mouscadet, Stephen Cullingford, Kurt Ma, Stefanie Gassel, Suzi Kim, Andrew Moffat, Millicent Maier, Marco Revelant, Joe Letteri i Karan Singh.
Powyższy tekst jest bezpośrednim przekładem artykułu opublikowanego 21 grudnia 2022 roku przez Mike’a Seymoura w serwisie branżowym fxguide.com.
My, PCC Polska Spółka Jawna, i nasi partnerzy, korzystamy na naszych stronach z plików cookies (ciasteczek). Część z nich jest niezbędna dla funkcjonowania stron. Pozostałe możemy wykorzystywać do:
- analizy w jaki sposób korzystasz z naszej strony,
- personalizacji prezentowanych Ci treści,
- marketingu, reklamy i na potrzeby mediów społecznościowych.
Te pliki cookie sa niezbędne dla poprawnego funkcjonowania strony internetowej. Umożliwiają działanie podstawowych funkcji takich jak nawigacja na stronie, preferencje prywatności, logowanie, wypełnianie formularzy i zapytań o ofertę. Nie mogą być wyłączone w naszej witrynie.
Preferencje
Służą do przechowywania informacji o preferencjach, o które nie prosi subskrybent lub użytkownik. Wykorzystywane są w celu interakcji z użytkownikiem, który wcześniej odwiedził witrynę.
Statystyka
Te pliki cookie pomagają nam zrozumieć, w jaki sposób różni użytkownicy zachowują się na stronie, gromadząc i raportując anonimowe informacje.Przechowywanie techniczne lub dostęp, który jest używany wyłącznie do anonimowych celów statystycznych. Bez wezwania do sądu, dobrowolnego podporządkowania się dostawcy usług internetowych lub dodatkowych zapisów od strony trzeciej, informacje przechowywane lub pobierane wyłącznie w tym celu zwykle nie mogą być wykorzystywane do identyfikacji użytkownika.
Marketing
Marketingowe pliki cookie służą do śledzenia użytkownika w witrynach internetowych, aby prezentować mu odpowiednie reklamy, interesujące i zgodnie z profilem użytkownika. Są bardziej cenne dla wydawców i reklamodawców zewnętrznych.